


Los fundamentos teóricos y técnicos detrás de la construcción de la inteligencia artificial (IA), no de sus aplicaciones. Aquí tienes algunos tópicos claves que se centran en la base para la construcción de la IA, junto con una explicación de cada uno:
1. Fundamentos Matemáticos de la IA
La IA se basa en conceptos matemáticos avanzados que permiten el diseño y la optimización de algoritmos. Estos fundamentos son esenciales para entender cómo funcionan los modelos de machine learning y redes neuronales. Entonces incluyen diferentes áreas de las Matemáticas.

-
-
Álgebra lineal: Operaciones con matrices y vectores, esenciales para el procesamiento de datos y la optimización de modelos.
-
Cálculo diferencial e integral: Gradientes y derivadas, fundamentales para el entrenamiento de redes neuronales mediante el descenso de gradiente.
-
Probabilidad y estadística: Modelado de incertidumbre, distribuciones de probabilidad y técnicas como el teorema de Bayes, clave en algoritmos de clasificación y predicción.
-
Optimización: Algoritmos para minimizar funciones de pérdida y ajustar parámetros en modelos de machine learning.
-
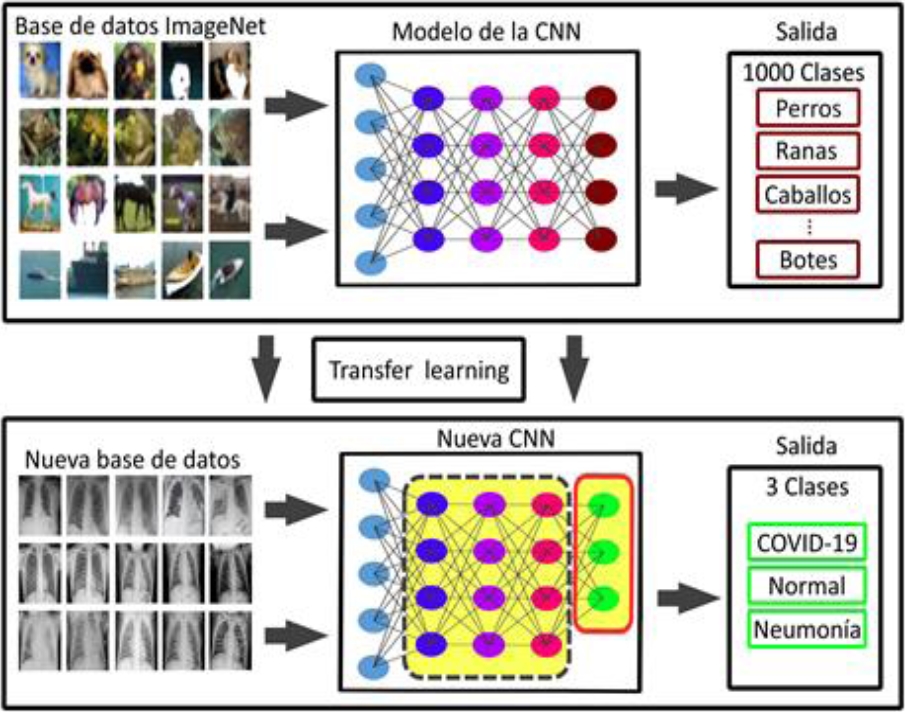
2. Arquitecturas de Redes Neuronales
Las redes neuronales son la base de muchos sistemas de IA modernos. Su construcción implica diseñar capas y conexiones que permiten a la máquina aprender patrones complejos a partir de datos. Dentro del estudio de redes neuronales se enfocan en diferentes áreas.
-
-
Perceptrones y redes neuronales simples: La unidad básica de una red neuronal, que simula una neurona biológica.
-
Redes neuronales profundas (Deep Learning): Uso de múltiples capas ocultas para capturar relaciones no lineales en los datos.
-
Redes neuronales convolucionales (CNN): Especializadas en procesar datos estructurados en cuadrículas, como imágenes.
-
Redes neuronales recurrentes (RNN) y LSTM: Diseñadas para trabajar con secuencias, como texto o series temporales.
-
Transformers: Arquitecturas basadas en mecanismos de atención, revolucionarias en el procesamiento del lenguaje natural.
-
3. Algoritmos de Aprendizaje Automático (Machine Learning)
La gran mayoría de tecnologías emergentes poseen módulos que les permiten interactuar de forma más autónoma y humanizada. Dentro de las múltiples áreas que comprende la IA, se encuentra el Aprendizaje Automático o Machine Learning (ML).
Los algoritmos de ML pretenden que las computadoras aprendan a tomar decisiones sin la necesidad de ser programadas explícitamente. Es por ello que hoy en día podemos escuchar acerca de autos de conducción autónoma, agentes virtuales de atención al cliente ( chatbots ), sistemas de recomendación y recolección de datos (Netflix, Google, Facebook).
Para adentrarnos más al mundo de ML, es importante conocer la clasificación de sus algoritmos. Dependiendo de las necesidades del problema, el ambiente en el que se van a desarrollar y los factores que afectarán la toma de decisiones, podemos encontrar distintos tipos de algoritmos de aprendizaje, entre los cuales vamos a hablar de 3 de ellos: supervisado, no supervisado y por refuerzo.
-
-
Aprendizaje supervisado: Modelos que aprenden a partir de datos etiquetados (por ejemplo, regresión lineal, árboles de decisión, SVM).
-
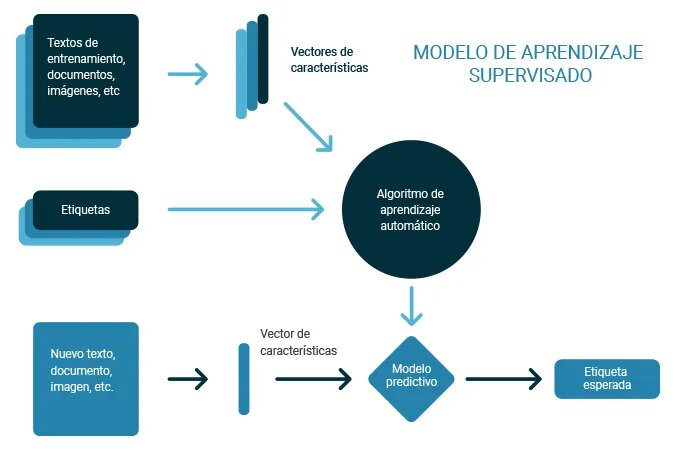
- En los algoritmos de aprendizaje supervisados se genera un modelo predictivo, basado en datos de entrada y salida. La palabra clave “supervisado” viene de la idea de tener un conjunto de datos previamente etiquetado y clasificado, es decir, tener un conjunto de muestra, el cual ya se sabe a qué grupo, valor o categoría pertenecen los ejemplos. Con este grupo de datos que llamamos datos de entrenamiento, se realiza el ajuste al modelo inicial planteado. Es de esta forma como el algoritmo va “aprendiendo” a clasificar las muestras de entrada comparando el resultado del modelo, y la etiqueta real de la muestra, realizando las compensaciones respectivas al modelo de acuerdo a cada error en la estimación del resultado. Por ejemplo, el aprendizaje supervisado ha sido utilizado para la programación de vehículos autónomos . Algunos métodos y algoritmos que podemos implementar son los siguientes:
- K vecinos más próximos (K-vecinos más cercanos)
- Redes neuronales artificiales
- Máquinas de vectores de soporte
- Clasificador Bayesiano ingenuo (Clasificador Naïve Bayes)
- Árboles de decisión
- Regresión logística
-
-
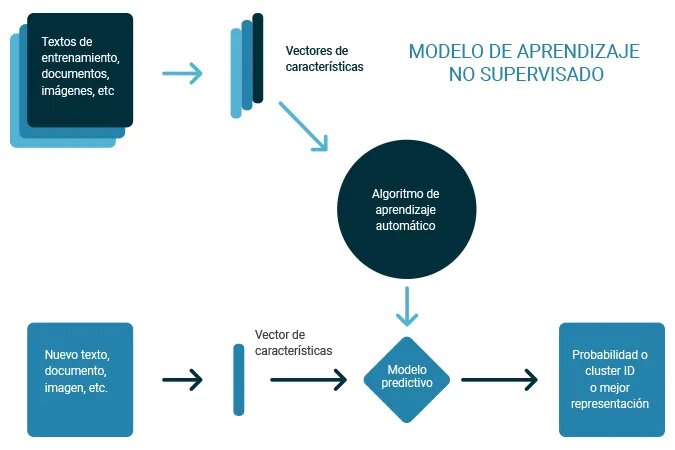
Aprendizaje no supervisado: Modelos que identifican patrones en datos no etiquetados (por ejemplo, clustering con k-means, reducción de dimensionalidad con PCA).
-
-
Los algoritmos de aprendizaje no supervisado trabajan de forma muy similar a los supervisados, con la diferencia de que éstos sólo ajustan su modelo predictivo tomando en cuenta los datos de entrada, sin importar los de salida. Es decir, a diferencia del supervisado, los datos de entrada no están clasificados ni etiquetados, y no son necesarias estas características para entrenar el modelo. Dentro de este tipo de algoritmos, el agrupamiento o clustering en inglés, es el más utilizado, ya que particiona los datos en grupos que poseen características similares entre sí. Una aplicación de estos métodos es la compresión de imágenes . Entre los principales algoritmos de tipo no supervisado destacan:
- K-medias (K-means)
- Mezcla de Gaussianas
- Agrupamiento jerárquico
- Mapas auto-organizados
- Aprendizaje reforzado: Algoritmos que aprenden mediante interacción con un entorno y retroalimentación por recompensas (por ejemplo, Q-learning, Deep Q-Networks).
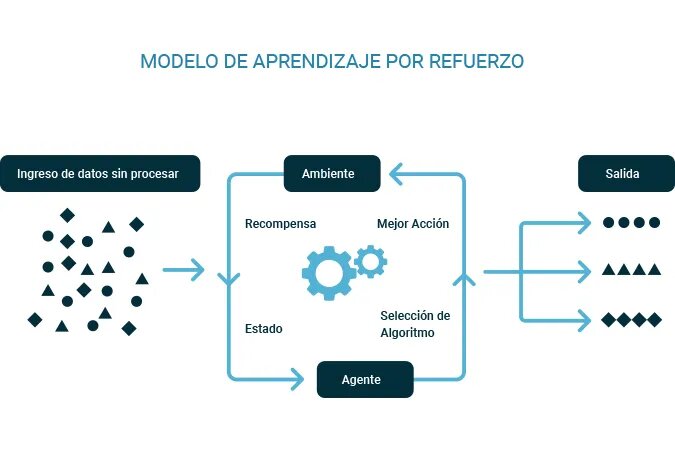
Los algoritmos de aprendizaje por refuerzo definen modelos y funciones enfocadas en maximizar una medida de “recompensas”, basadas en “acciones” y al ambiente en el que el agente inteligente se desempeñará. Este algoritmo es el más apegado a la psicología conductista de los humanos, ya que es un modelo de acción-recompensa, que busca que el algoritmo se ajuste a la mejor “recompensa” dada por el ambiente, y sus acciones por tomar están sujetas a estas. recompensas. Este tipo de métodos pueden usarse para hacer que los robots aprendan a realizar diferentes tareas. Entre los algoritmos más utilizados podemos nombrar:
- Programación dinámica
- Aprendizaje Q
- SARSA
Otros métodos de entrenamiento que se derivan de los primeros son los siguientes.
- Aprendizaje por transferencia: Técnicas que permiten reutilizar modelos preentrenados en nuevas tareas.
- Regularización y técnicas de generalización: Métodos para evitar el sobreajuste (overfitting) y mejorar el rendimiento en datos no vistos (por ejemplo, dropout, early stopping).
Otros Tópicos Relacionados con la Construcción de la IA:
-
Preprocesamiento de Datos:
-
Limpieza de datos, normalización y transformación.
-
Ingeniería de características (feature engineering) para mejorar el rendimiento de los modelos.
-
-
Funciones de Pérdida y Métricas de Evaluación:
-
Diseño de funciones de pérdida (loss functions) para guiar el entrenamiento.
-
Métricas como precisión, recall, F1-score y AUC-ROC para evaluar modelos.
-
-
Hardware y Software para IA:
-
Uso de GPUs y TPUs para acelerar el entrenamiento de modelos.
-
Frameworks como TensorFlow, PyTorch y Keras para implementar redes neuronales.
-
-
Teoría del Aprendizaje Computacional:
-
Límites teóricos del aprendizaje automático.
-
Comprensión de la capacidad de generalización de los modelos.
-
-
Interpretabilidad y Explicabilidad de Modelos:
-
Técnicas para entender cómo los modelos toman decisiones (por ejemplo, SHAP, LIME).
-
Diseño de modelos transparentes y éticos.
-
- Novedad
- Programación | Programas, aplicaciones

Publicación by Maqui is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 Internacional







{kind=link}
Tremendo cambio hicieron los chinos con su nuevo producto de IA.
Si, hicieron una revolución, mejorando la IA con DeepSeek.